Screenshots and a Terrorism Case
Published: June 9, 2017
A Hunchly user alerted me to a terrorism case here in Canada that had a lot of relevant background on how law enforcement in some cases collects, and preserves evidence during online investigations and how that evidence is submitted to the Court.
This blog post will examine some of the arguments from both sides of the fence. This is not a thrashing of SnagIT (great tool and arguably the best screenshotting software on the market), but just my thoughts on this case and some words of caution and tips.
Of course there are spots where Hunchly is designed precisely to address concerns or problems raised in the case. I will certainly point these out simply because I get asked about them a lot.
I also want to note that this is not an analysis on how the RCMP moved evidence around, certified it, or anything else. I am not a member of law enforcement, nor a lawyer, and thus have no training or qualifications to pose my opinion on those matters.
The Background
You can read the court record here. The background is that there were various projects that were started by the RCMP that stemmed from the attacks in Ottawa in 2014. It appears that a large part of these projects were performing OSINT to identify potential threats to national security. No shocker there, we would expect our federal police agency to be doing this.
This particular case is interesting because it started with the identification of Hamdan’s Facebook account and relevant posts that warranted a follow up investigation.
I encourage you to read the full record, it is pretty interesting.
Analysis
I will pluck out the pieces that caught my eye the most:
[10] Cst. Johnson did not attempt to capture any source code or metadata. He had no knowledge about how to do that. He believed that the captures he made would be reviewed by investigators who would decide how to proceed with the investigation. He knew it was possible to obtain Production Orders to get information about and preserve electronic files. He also understood it was possible to make a request to Facebook in the United States to obtain Facebook’s records about pages and profiles through the Mutual Legal Assistance Treaty (“MLAT”) between Canada and the United States.
This is interesting. I am not entirely sure what “metadata” refers to in this case but it could mean the metadata in photos or other things on the page. The source code argument is also an interesting one in that it could mean the HTML or the Javascript (Hunchly captures both, with the exception of not making external calls to retrieve Javascript files).
This is a slippery slope but it speaks to the fact that with proper full content captures some of these arguments could have been shut down. Without knowing what metadata they were after, it is tough to say what the real meat of this argument is.
[16] C.M. Spearman testified that all of the screenshots and their printed versions are true and accurate copies of the originals. However, she acknowledged that there are some qualifications to that comment. First, many of the captured Timelines have “banner artifacts” that cover up parts of the Timeline pages that would have been visible to a Facebook user. In some cases those artifacts hide text that would have been visible to a user. The artifacts are created by Snagit and Awesome Screenshot as they are not able to properly capture a scrolling page. The banner that should remain at the top of the Facebook page or profile appears superimposed over other parts of the image.
Right. This is an ongoing problem with most capturing systems, that dreaded scrolling of Facebook pages (Twitter and others fall in here too).
Does Hunchly have this nailed 100%? No.
Do we have it really close? Yes.
There have been isolated cases where users have reached out because there are artifacts, namely how CSS renders some pieces of profile pages, that have been captured. The solution is often to revisit the Facebook page on the mobile Facebook site, and to do the capture from there. The reason is that they use far less styling and dynamic content on the mobile site and you will run into less of this artifact problem.
However, where Hunchly is superior is that the CSS artifacts applied that covers content, does not cover the underlying source content. This means that you can view the captured MHTML and examine the underlying content regardless of the visual artifacts.
You can’t do this with screenshots.
[18] C.M. Spearman often made notes about the captures. These included the time of the capture, the unique web address or “URL”, and the unique ID number that Facebook assigns to each account when it is created. For four of the Key Posts, she did not make a note of or otherwise obtain the URL. Usually the ID number for the Facebook account was included in the URL, but even if it was not, the ID number was obtained for each of the Key Posts C.M. Spearman captured.
This is a key feature of Hunchly. You don’t have to think about noting URLs, timestamps, or hashes. This is done automatically, and it is done precisely for this reason. This is not a criticism of the officer here, it is simply human nature. We have people calling us, stopping by our desks, emails abound and, as humans, we are imperfect beings.
Hunchly automates the tedium for this reason.
[19] After Mr. Hamdan’s arrest, C.M. Spearman was told that the captures may become exhibits and she created what she called a master evidence list which listed in chronological order all of the captures she made. Her list compiled the information available to her, which included the original captured files, where those were retained and the .pdf files as well as her notes. She also attempted to set out the date and time of both posting and capture of the posts. This was not straightforward, in part because the posts were made in Fort St. John and captured in Surrey, B.C., which are in different time zones when Pacific Standard Time moves to daylight saving time. Determining the time of posting is also complicated by how Facebook notes the time of a post.
How relevant is this for this particular case? Not really in my opinion. Whether they said something at 5pm or 6pm is irrelevant when they are discussing terrorism or supporting a terrorist organization.
Now, if you were trying to pin down a specific time/location for a suspect for a homicide, robbery, assault, etc. then it becomes important.
Why am I mentioning this?
Defense attorneys have the ability to question everything. That is how the scales of justice remain balanced. So it is imperative that you understand how you are collecting information, including how your target sites are storing timestamps (lots are UTC, do your own experiments, test, validate, repeat).
We are exploring how to sort some of this out automatically, but it is a thorny problem. Stay tuned.
[20] As C.M. Spearman was monitoring the pages associated with Mr. Hamdan, the task was complicated by Facebook routinely shutting down the profiles and pages. This is presumably because the content of the pages and profiles violated the Facebook terms of use. C.M. Spearman was thus required to locate other pages or profiles administered by the same person. She was able to do this because he would identify a new page for friends and followers. Accordingly, a series of concurrent and consecutive pages and profiles was created by the same administrator.
Yup. I have beat this drum for a long time. Having full content captures of pages are much more superior than screenshots, especially when your target’s profile runs the risk of getting shut down. This is really common in extremist accounts of all kinds.
Full content captures enable you to go back and look at links to other profiles, groups, or other connecting material.
You can’t do that with screenshots.
[21] In cross-examination, Cst. Johnson and C.M. Spearman agreed that they did not take steps to ensure that the computers they used were free from spyware or malicious viruses. The computers and laptops were maintained by the RCMP IT department and were, to their knowledge, in good working order. Neither took steps to clean all data from the hard drives of the laptops used to access the Internet. However, they had no difficulty using the web browser and capturing posts. C.M. Spearman does not know if other RCMP employees were using the laptops for other investigations during the time she used them. C.M. Spearman did install anti-virus software on one of the laptops when she noted that the existing version was out of date. She took no special steps to uninstall the old anti-virus software when she installed the new version.
Yeah, we are going to see more of this. Sad but true. The argument that your computer could be compromised and thus could compromise the evidence is something you should expect attorneys to start asking. Unfortunately for everyone, it is bullshit. Anti-virus is not a guarantee that you are not compromised. In fact, I would argue that anti-virus could increase your chances of being compromised. Just ask Tavis Ormandy.
The argument is also weak in a sense that if there is malware on the machine that is specific to the investigation, it would tend to be that it would be your target or a member of your target’s organization that developed it to specifically target your investigation. If they know this much about you, your investigation and your evidence collection techniques, your law enforcement organization has much larger problems.
The co-mingling of investigations is a larger problem (the officer not knowing if someone else used the computer for other investigations) but this comes down to case management. Separate cases and evidence logged into them on the same system is not problematic in any sense that I can see.
[31] Kevin Ripa gave expert evidence for the defence. He was qualified as an expert in the field of digital forensic analysis, and internet and webpage architecture. He was highly critical of the way in which the Electronic Documents were collected and preserved. He identified forensic-grade software programs that can collect information from webpages, including Facebook accounts, for evidentiary purposes and gave an estimate of the cost of purchase: “X1 — Social Discovery” ($2,000), “Inspector Hunchly” ($150) and “WebCase”. He said that these programs are designed to collect all data including text, photos, video, animation, as well as source code and metadata. The programs also correlate date and time. If evidence is collected using forensic-grade software, then it is possible to “hash” the file to insure that nothing in the file has changed. If all of the data including the source code is collected, then it is possible to examine the webpage as it existed online; it is possible to expand posts and watch videos.
Although I appreciate the mention, parts of this statement are technically incorrect.
If you preserve a Facebook page with the links intact (specifically the Read More, Comments, etc.) you will NOT be able to expand those comments in a local copy taken by Hunchly.
I cannot comment on X1 or other tools, but from a technical standpoint it remains the same.
Why is that?
Let’s look at our browser window when examining this in animated GIF style:
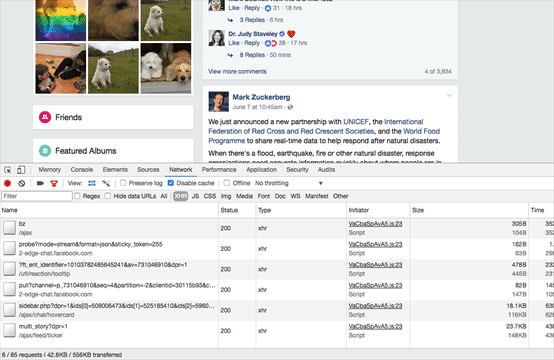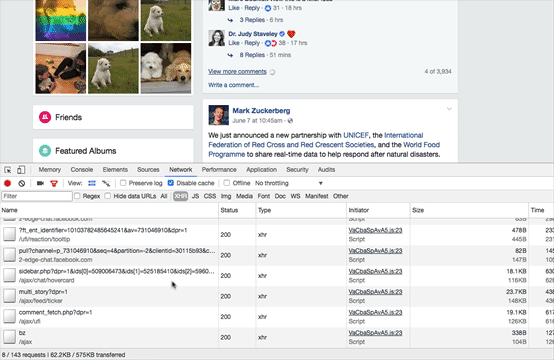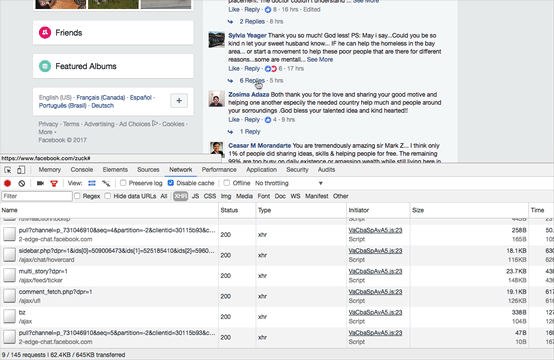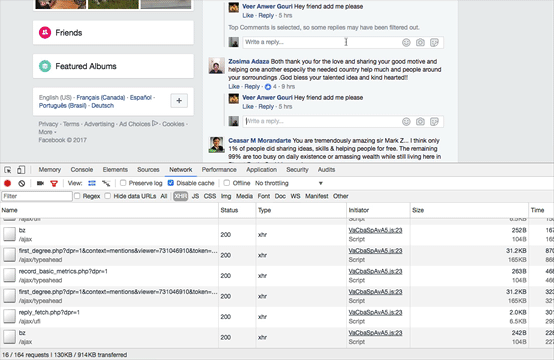
You see that? Dynamic websites like Facebook and Twitter will only load content after you click on it. That traffic you see in my Chrome browser is pulling in the additional comments after I click the link.
In a local copy of the page, this click would have to reach back out to Facebook to load those comments. Capturing all of the source code does not solve this problem, you still need to click on the expanding links before you do your evidence capture. If the target profile has been removed, you are screwed. There is little the officer could have done aside from expanding all comments and then preserving the page at that time.
There are Chrome and Firefox extensions that will do this expansion for you, but use at your own risk.
Hunchly does not, and will not, perform automated browser interactions on your behalf for a multitude of reasons.
[33] In addition, he said that the way in which the evidence was transferred and stored raises the possibility that it has been altered or corrupted. There is no way to compare it against the original electronic data. He stressed the importance of collecting electronic evidence in a way that preserves the original data so that it can be compared to any subsequent copies or reproductions. This is done by “hashing” the data when it is first collected. No attempt was made to do that by either Cst. Johnson or C.M. Spearman.
Yup. Hashes matter in court even though most of us know that you can modify evidence, re-hash and submit again thus not preventing the modification of evidence. We know that this could be the case with DNA evidence, or a whole bunch of other things but it is generally accepted that with some baseline accepted best practices we prevent it. Hashes matter.
Hunchly hashes (SHA-256) of all content it encounters.
At the end of the day, I am not a lawyer so I can’t comment on what the Court’s final decision actually means. It looks like everything (the collection, preservation, etc.) is all up for debate at trial. It should be interesting to see how this all plays out.
Closing Thoughts
Naturally there have been countless investigations that include OSINT or some form of online evidence collection. This is clearly not going away. Keep in mind that most OSINT-driven investigations are backed with corroborating closed source information such as the materials provided by Facebook, confidential informants, surveillance or intercepts.
I have always had my concerns with automated online evidence collection (evidence is not intelligence) software. How would you be able to speak about the software that went out and collected it?
I know of some automated solutions that routinely miss massive amounts of information and then tell you “All Posts Collected”.
…or they pull in information that is just blatantly not part of the target’s account or online presence.
…or Facebook makes a change on their site and the software fails to download any posts.
…or if you run them twice in a row against the same account they come back with a different number of posts each time.
Imagine the nightmare of explaining some of this while you’re on the stand.
Although I teach an automated collection course, I always stress that gathering large amounts of data is designed to help you pick out that signal from the noise. At which point, you inevitably need to open your browser and do the investigative work. Use automation where appropriate, be cautious with how you use the results.
I personally advocate that manual investigations and analysis should remain just that: manual. Having an investigator poring over content, digging into relationships, and examining posts is an activity best left for a human. We just suck at documenting some of those activities.
For me this was something that Hunchly did for me (I originally built it as a tool only for myself). What I see is what I get. I know I browsed to a URL at a specific time, and what content was on that URL. Hunchly is not automating the collection it is automating the capture and cataloguing.
Hunchly is not perfect, but no software, or law, really is.
— Justin
ps. I know folks will have varying opinions on this case and my analysis, comment below or shoot me an email to share your opinion with me: justin@hunch.ly
